RION - Raw Internet Object Notation
A fast, compact and versatile data format for modern internet applications.
Today we live in a 24/7 data driven world where it is estimated that on average we generate around 2.5 quintillion bytes of data per day, a lot of that data being generate by users of popular services from household names such as Google, Facebook, Amazon, LinkedIn, Netflix etc. A recent report by Cisco predicts the following:
● By 2020, the gigabyte (GB) equivalent of all movies ever made will cross the global Internet every 2 minutes.
● Globally, IP traffic will reach 511 terabits per second (Tbps) in 2020, the equivalent of 142 million people streaming Internet high-definition (HD) video simultaneously, all day, every day.
Cisco also recently updated their Global consumer web, email, data traffic prediction for 2016–2021.
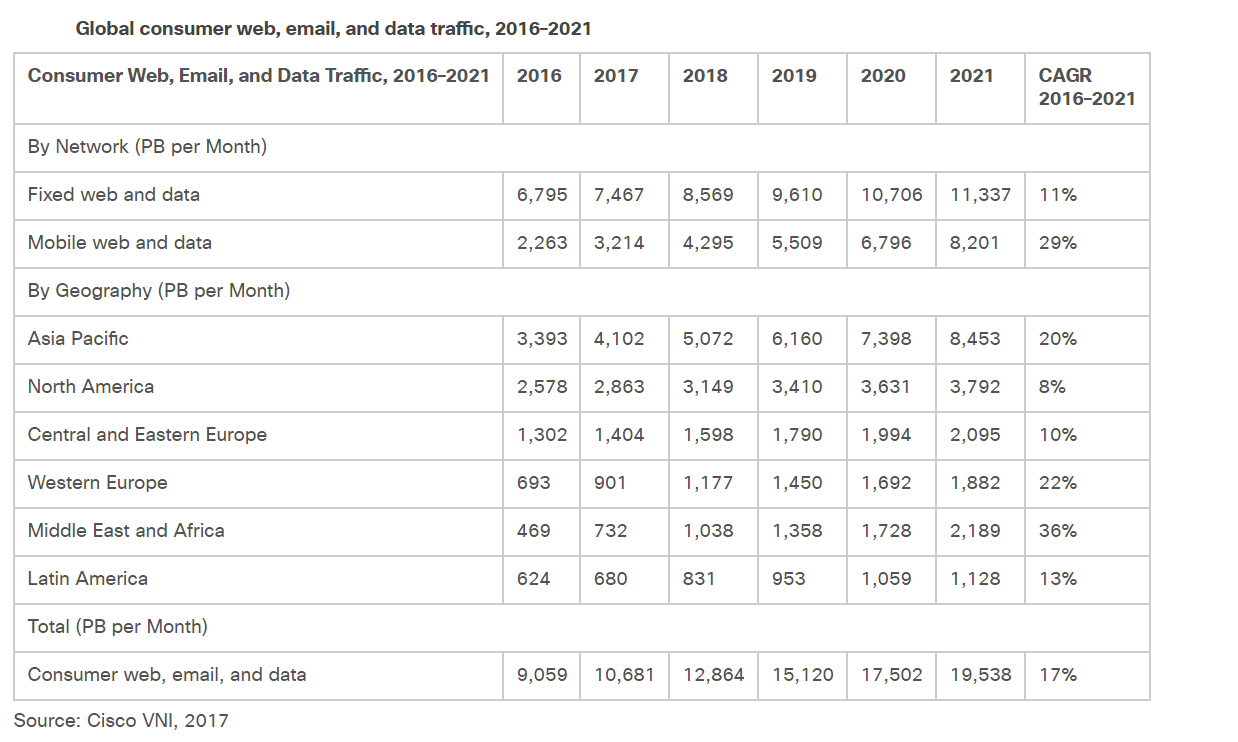
Another interesting prediction by Cisco relevant to this post is related to file sharing for 2016–2021.
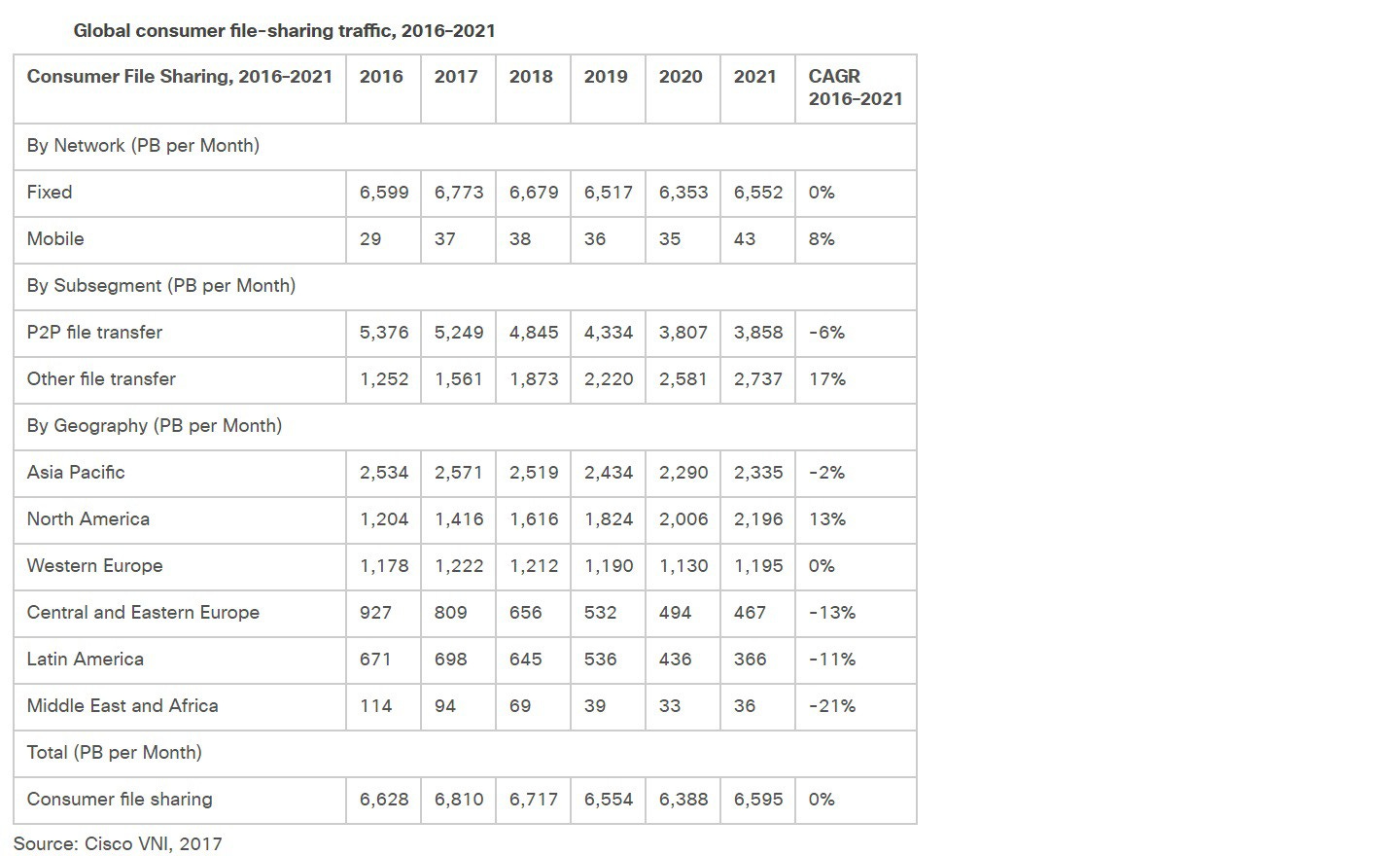
Building smarter, scalable and fault tolerant applications that handle such a high volume of data is a huge challenge, but also represents a big opportunity for both startups and consumers. For disruptive startups (e.g. Blochchain startups) addressing big markets such as financial services, it puts them in a strong position to challenge the big incumbent financial institutions that mostly rely on centralised legacy technologies that were not designed for the current 24/7 explosion of connectivity and big data generated by consumers. For consumers, it opens up more choice and better quality of services at more competitive pricing than with the big incumbents.
Why do we need a new data format?
Recently we have witnessed a sensational return of distributed systems to the mainstream software industry. Microservices being without doubts amongst the hottest hypes and buzzwords in the software industry right — a proof of this is the presence of microservices in the so — called Gartner Hype Cycle! In this post we asked whether early stage startups should adopt microservices.
A couple years ago the benefits of distributed computing seemed to be only centered around the use case of academic research. A common use case often cited is the ability of scientists tackling hard scientific problems in fields such as genomics via cross disciplinary/institutional collaboration using grid computing to easily perform huge data processing/analysis tasks that otherwise would take months to accomplish.
With distributed systems now in the mainstream software industry. At Nanosai we are of the view that when exchanging data between nodes in a distributed system, it is very advantageous to encode data using a fast, compact and versatile data format. We felt that the existing formats (e.g. Protobuf, CBOR, MessagePack, JSON) were not versatile and fast enough for the type of use cases that we envisioned distributed systems of the future will be. Other reasons include the following;
A fast data format is faster to read and write (deserialize and serialize) for the communicating nodes. RION can even be traversed in its binary form if you need maximum speed.
A compact data format requires less bytes to represent the encoded data. Fewer bytes requires less network bandwidth and can thus be transferred faster across the network. A compact data format is also an advantage when reading and writing it.
A versatile data format is a data format that can be used for as many use cases as possible. This minimizes your need for finding or inventing other data formats.
RION was designed with exactly the above reasons in mind. In fact, we had several other design goals for RION. These are described in the text RION Design Goals.
RION Background Story
Before we define RION in the next section, let us mention that it was was originally launched using the name ION - but about a year later Amazon released a similar data format also called ION. After a while we decided to rename our ION format to RION, to distinguish between the two.
Although Amazon's ION format is similar in encoding to our RION format, we do not think Amazon copied our ION format and tried to "steal" the name. Here is why: When we published our ION format the first time, someone told us that Amazon had an internal data format with the name ION. However, since Amazon had not released it, we continued with the name ION. However, about a year later Amazon released their ION format - so after some time we decided to change name to RION.
So What Is RION?
RION is binary data format - it uses a binary encoding to make it faster to read and write, more compact, and to make it possible to embed binary data. RION's encoding is described in the text RION Encoding.
RION vs Other Data Formats
RION is a data format which is similar to a binary version of JSON. In that respect RION is similar to MessagePack, CBOR and Amazon's RION but with a few minor, beneficial differences.
We have a more detailed description of how RION compares to other data formats in the text RION vs. Other Formats.
Since RION is similar in encoding to MessagePack, CBOR and Amazon's ION, we expect the read and write speeds to be comparable to that of these formats. We have made some comparisons already with Jackson's MessagePack and CBOR implementations and they confirm this expectation. You can see the results of this comparison in the text RION Performance Benchmarks.
However, RION is still different in a few areas than these data formats, and for the use cases that utilize these differences, the benefits can be big.
If you would like to play with RION, we`ve created RION Ops for Java - an open source toolkit for reading and writing RION encoded data.
Side note: RION is an integral part of our open source data streaming engine Stream Ops - that we are developing to solve the 1BRS Challenge. RION is also being deployed by our colleagues at Kähler AI.