

The One Billion Records Per Second Data Streaming Challenge
Challenge Background
The One Billion Records Per Second Data Streaming Challenge is a challenge to implement a data streaming engine that can process one billion records per second. The abbreviation for this challenge is 1BRS Challenge. The 1BRS challenge was issued by Nanosai.com on September 1st 2019 and it`s being sponsored by our sister company Kähler AI.
At one billion records per second and above, data streaming becomes applicable to a whole new class of problems, and the data streaming engines can offer a more advanced set of features.
To achieve data streaming at one billion records per second you will have to rethink the design of data streaming engines and stream processing APIs. Many of the current designs won’t scale to one billion records per second. They have too much overhead per record to be able to get there.
Our data streaming engine can work in either embedded or networked mode. The 1BRS challenge is for embedded mode, but we will try to push the limits of networked mode data streaming too. Naturally, the speed of the two modes are somewhat related, although network speed is often the biggest limiting factor of data streaming over a network.
Challenge Requirements
The challenge goal - to “process one billion records per second” - is somewhat open to interpretation. Therefore we have specified what we mean by “process” and “record” in this section.
The data streaming engine used must be a general purpose data streaming engine - not one specifically designed for this challenge.
The benchmark must run on a single node! A single computer - not a cluster of computers. The computer can be beefed up - but should not be a supercomputer. A big, yet realistically sized server is acceptable.
The processing means reading the records and processing them (e.g. calculating sums, averages or whatever the use case calls for etc.).
Records should be read from permanent storage before being processed - not simply be stored in memory. We assume the records already exists on permanent storage. Writing the records is excluded from this benchmark.
The processing use case should be based on a realistic use case - not a use case designed for this challenge.
A record can be of any size, from 1 byte and up, as long as it correctly models a record needed by the use case.
As you can see, simply writing 1 billion random byte values directly in memory would not meet the challenge requirements. First of all, the records must come from permanent storage of some sort. Second, a general purpose streaming engine will have a hard time storing even single byte records as just 1 byte on the disk. A general purpose streaming engine typically need some kind of record delimiter to know where each record starts and ends.
We do allow some level of flexibility in meeting this challenge though. It is allowed to optimize your records specifically for the use case - as long as the record still contain enough information to properly support the use case. In fact, we expect to optimize records for the use case - just like you would do in a real life project.
Our Challenge Use Case
The use case we will be using for this challenge is processing of order items from e.g. an online web shop. The processing of the records will calculate:
Total revenue
Revenue per product
Revenue per order
Revenue per customer
Each record will represent one order item (one product inside one order). As long as we can calculate the above numbers, we are free to design the records and streams to achieve maximum throughput.
Nanosai Stream Ops
We, at Nanosai, will attempt to overcome the 1BRS challenge with our Stream Ops data streaming engine implemented in Java. Stream Ops is open source and available on GitHub.
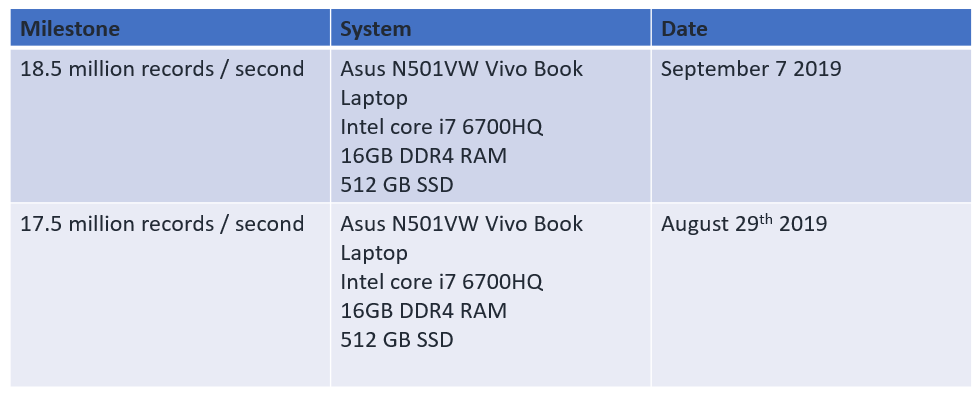
Benchmark Milestones
We`ll be posting updates to our efforts on this page as the project progresses - see our first humble benchmark below!:)
Would you like to take part in the challenge and share your benchmarks with us? Please fill out this form (less than 60 seconds) so we can follow up with you on how to participate and share your benchmarks with our team.
Many thanks,
Nanosai.com team